
Over the last few weeks, I’ve been working on the next step of my portfolio project: setting up a pre-production environment on AWS. Instead of just running the service locally or on a single server, I wanted to design an infrastructure that is closer to a real-world production setup, with scalability, automation, and reproducibility built in.
The goal of this post is to walk through how I deployed this service into production-like conditions on AWS using Terraform and GitHub Actions. Instead of relying on manual configurations in the AWS console, I went fully Infrastructure as Code (IaC) to ensure consistency and make deployments repeatable.
In this post, I’ll cover:
How I structured the Terraform project to bootstrap global resources and provision environment-specific infrastructure.
How the service runs on ECS (Fargate), backed by RDS and MSK (Managed Kafka).
How GitHub Actions automates the build, deployment, and infrastructure provisioning process.
This won’t be an exhaustive deep dive into every Terraform parameter, but rather a practical, step-by-step example of how to set up a production-ready environment for a real application. If you want to explore the full implementation in detail, all the code is available here: github.com/egobb/order-tracking .
General Architecture
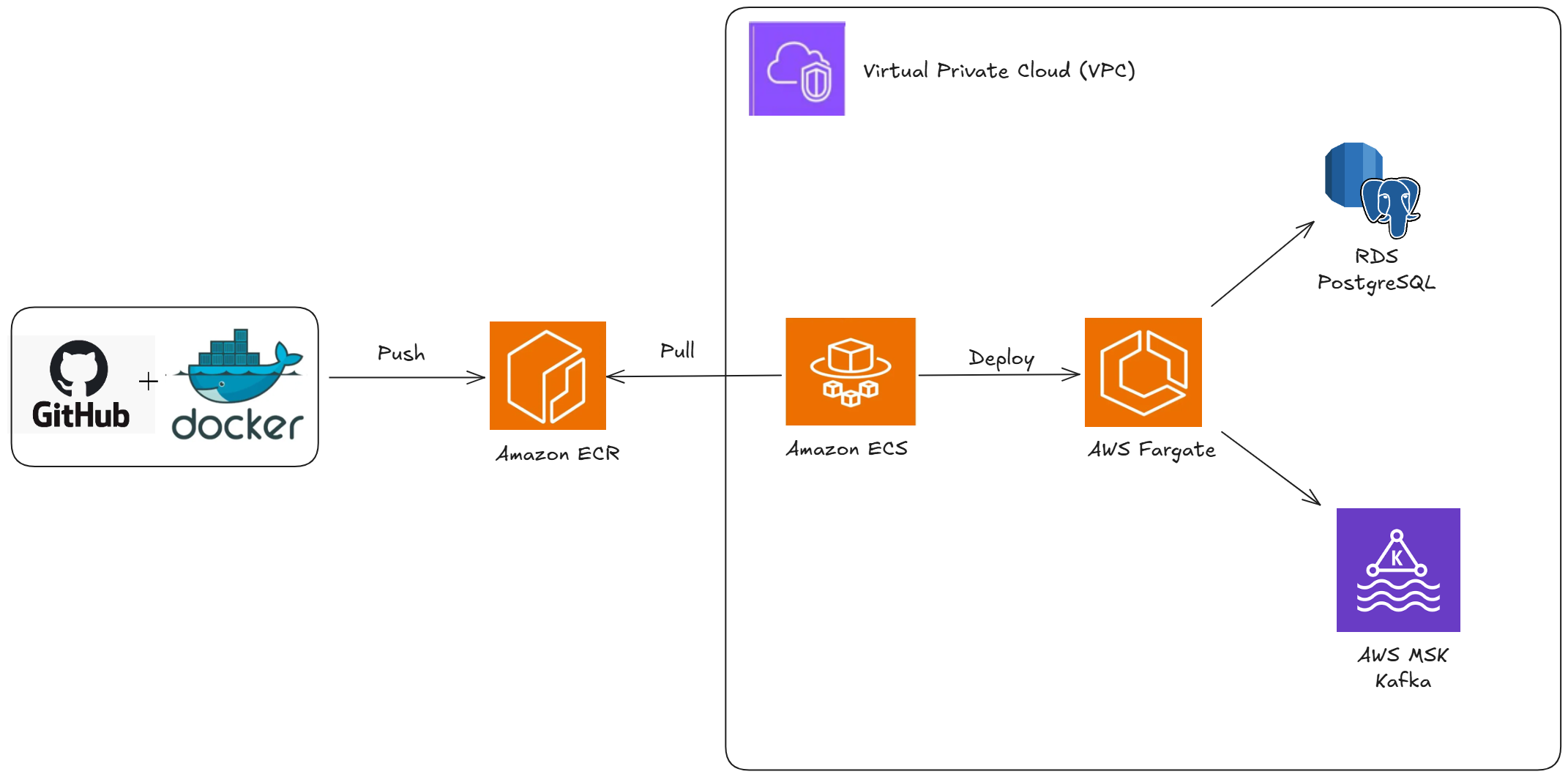
Before jumping into the Terraform code, let’s take a look at the overall architecture of the application. The goal was to design a cloud-native setup that mimics what you would expect in a production-ready environment, while still being flexible enough for pre-production testing.
At the core, the service is a Spring Boot application running inside Amazon ECS (Fargate). The application image is built and stored in Amazon ECR, and ECS pulls the latest version during deployments.
For persistence, the application connects to a PostgreSQL database on Amazon RDS, while asynchronous communication is handled through Amazon MSK (Managed Kafka). Logs and metrics are collected in Amazon CloudWatch to monitor the health of the application.
All resources are deployed inside a custom VPC. Since this is a pre-production environment, I configured public subnets with strict security group rules. This makes it possible to access and debug the services remotely, which is critical during testing, while still enforcing tight access control to avoid unnecessary exposure.
The diagram below illustrates the architecture at a high level:
Terraform Project Structure
infra/
├─ bootstrap/ # Run ONCE (or very rarely)
│ ├─ main.tf # Remote state (S3+Dynamo), GitHub OIDC, base IAM roles, ECR
│ ├─ msk-serverless.tf # MSK Serverless cluster (SASL/IAM)
│ ├─ rds.tf # RDS PostgreSQL + Secrets Manager secret
│ ├─ variables.tf # Bootstrap variables
│ └─ (other .tf: IAM, SGs, outputs)
│
└─ env/ # Per-workspace environment (dev, staging, prod…)
├─ main.tf # Backend per workspace + shared locals (naming/FQDN)
├─ bootstrap_outputs.tf # data.terraform_remote_state to read bootstrap outputs
├─ datasources-network.tf # locals: VPC + subnets from bootstrap
├─ alb.tf # ALB, Target Group, HTTP listener (base for HTTPS)
├─ networking.tf # Security groups for ALB and ECS service
├─ ecs.tf # ECS Cluster, Task Definition, Service
├─ sg.tf # SG→SG rules: ECS → RDS (5432), ECS → MSK (9098)
├─ outputs.tf # Useful outputs (ALB DNS, etc.)
└─ variables.tf # Environment variables (image, CPU/Mem, domain…)To keep the project clean and maintainable, I decided to split the Terraform configuration into two main parts:
infra/bootstrap/→ contains all the global resources that only need to be created once. For example, the S3 bucket that stores the Terraform state and the IAM roles required by the environment. This code is executed manually from my local machine only once.infra/env/→ contains the environment-specific resources that can change or evolve with each deployment. This includes ECS, RDS, MSK, VPCs, and all the networking configuration. This code is executed automatically through GitHub Actions whenever I want to deploy.
This separation allows me to avoid accidental re-creation of global resources and ensures that deployments remain safe and reproducible.
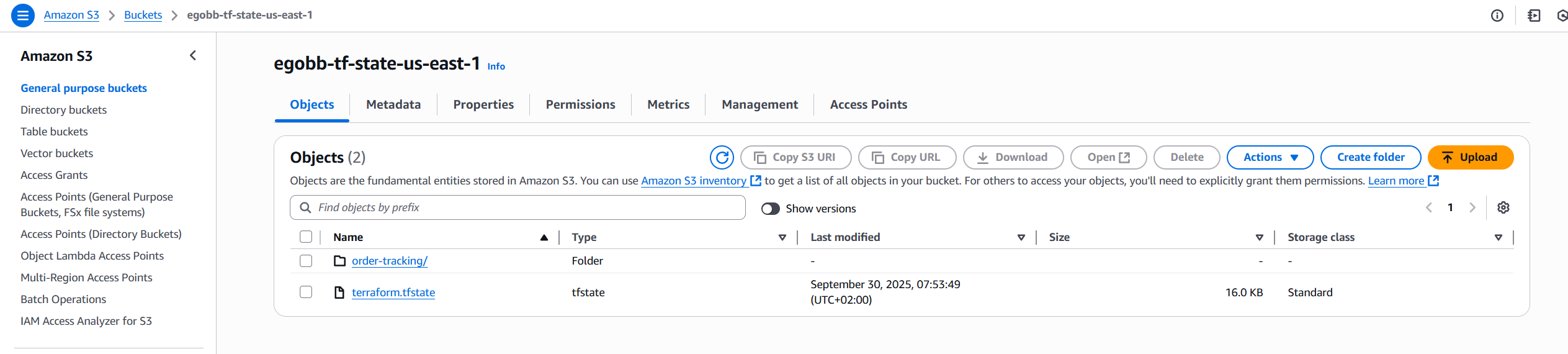
Here’s an example of how I configured the S3 bucket for Terraform state in the bootstrap stage:
resource "aws_s3_bucket" "tf_state" {
bucket = var.tf_state_bucket
force_destroy = false # Protect the state bucket from accidental deletion.
}
resource "aws_s3_bucket_versioning" "tf_state" {
bucket = aws_s3_bucket.tf_state.id
versioning_configuration {
status = "Enabled" # State relies on versioning for safe rollbacks.
}
}
resource "aws_dynamodb_table" "tf_lock" {
name = var.tf_lock_table
billing_mode = "PAY_PER_REQUEST" # No capacity management needed for lock tables.
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}Here’s the resulting S3 bucket in the AWS Console:
And here’s the corresponding DynamoDB table for state locking:

With this setup, Terraform uses S3 for state storage and DynamoDB for state locking, which prevents concurrency issues when running deployments.
Integration with Database and Kafka
A service rarely runs in isolation — it needs persistence and messaging to interact with the outside world. In this project, I integrated the application with Amazon RDS (PostgreSQL) for data storage and Amazon MSK (Managed Kafka) for event-driven communication.
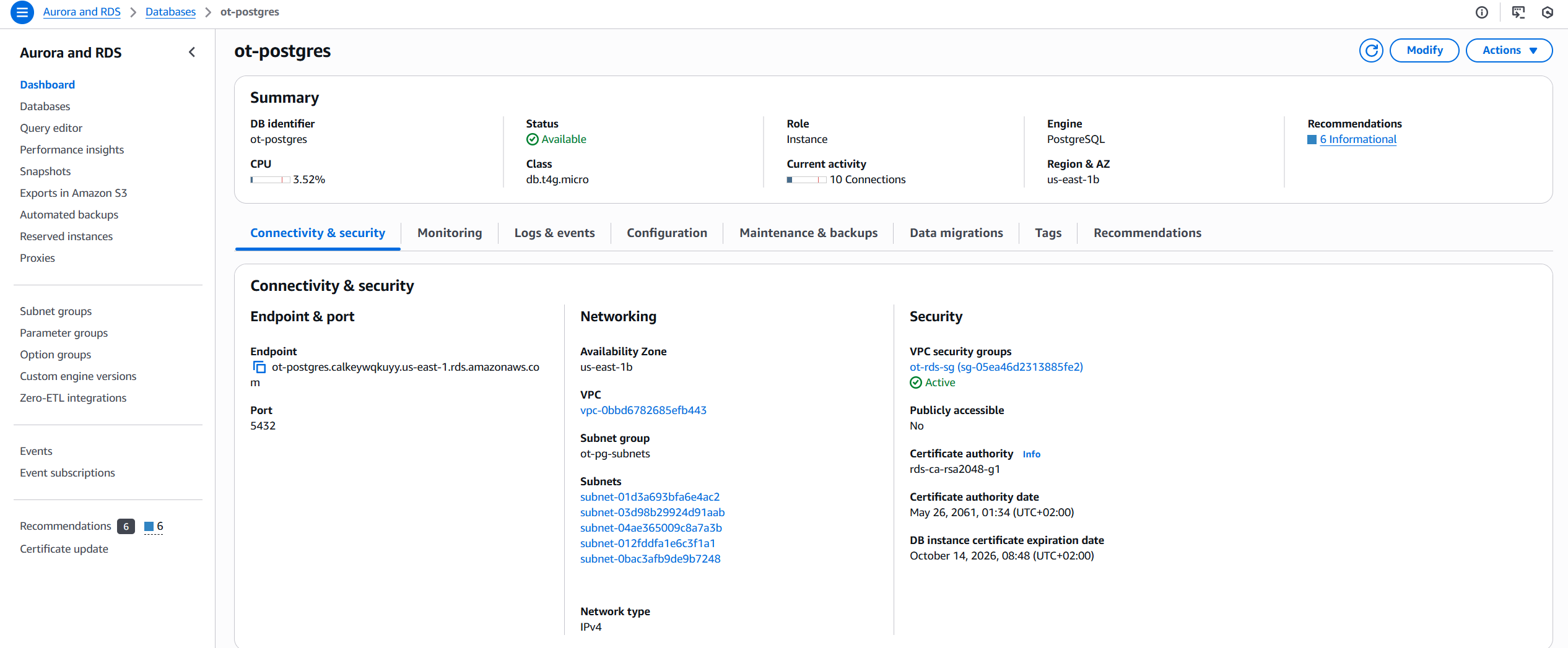
PostgreSQL with Amazon RDS
The database runs in public subnets inside the VPC. Although in a strict production environment RDS and MSK would normally live in private subnets behind NAT, for this pre-production setup I decided to place them in public subnets with tight security group restrictions. This simplifies remote debugging and connectivity during development while still maintaining security boundaries.
Here’s a simplified Terraform snippet for the RDS instance:
resource "aws_db_instance" "pg" {
identifier = "ot-postgres"
engine = "postgres"
engine_version = "16"
instance_class = "db.t4g.micro"
allocated_storage = 20
db_name = "ordertracking"
username = jsondecode(aws_secretsmanager_secret_version.pg.secret_string).username
password = jsondecode(aws_secretsmanager_secret_version.pg.secret_string).password
db_subnet_group_name = aws_db_subnet_group.pg.name
vpc_security_group_ids = [aws_security_group.rds.id]
publicly_accessible = false
# For bootstrap/dev I skip the final snapshot so `destroy` is quick and clean.
# In any persistent env, enable final snapshot and/or deletion protection.
skip_final_snapshot = true
}Here’s how the RDS instance appears in the AWS Console:
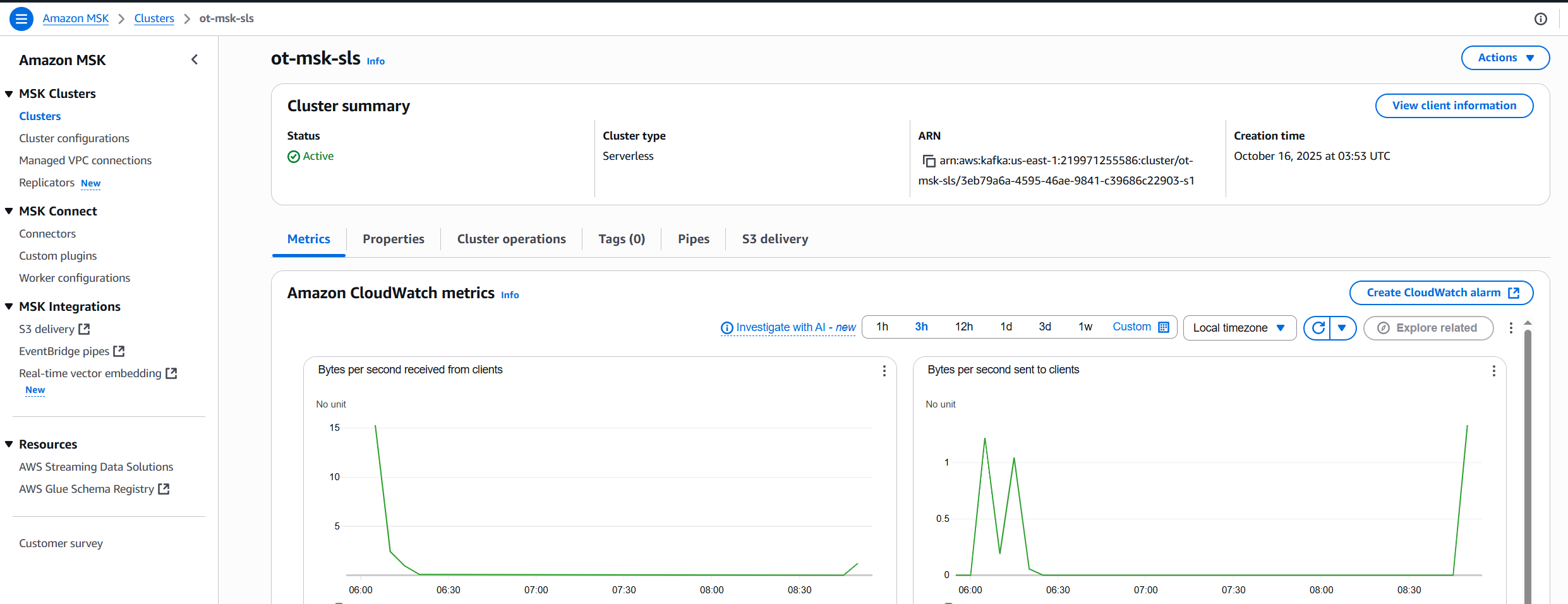
Kafka with Amazon MSK
For asynchronous messaging, the application uses Amazon MSK. Terraform provisions the Kafka cluster inside the same VPC, and ECS tasks communicate with it through the subnets.
Instead of managing brokers manually, I decided to use MSK Serverless. This reduces the operational overhead of capacity planning, simplifies IAM integration for authentication, and scales automatically with demand. For a portfolio project — and even for many production workloads — this is an efficient way to focus on the application rather than cluster management.
resource "aws_msk_serverless_cluster" "this" {
cluster_name = "ot-msk-sls"
vpc_config {
subnet_ids = local.public_subnet_ids
security_group_ids = [aws_security_group.msk.id]
}
client_authentication {
sasl {
iam {
enabled = true
}
}
}
}Here’s how the MSK cluster looks in the AWS Console:
Networking and Security
Even though this is a pre-production environment with public subnets, traffic is tightly controlled via Security Groups. Each SG is scoped to the minimum necessary ports and sources:
| Component | Inbound | Source | Notes |
|---|---|---|---|
| ALB | 80/443 | 0.0.0.0/0 (or your CIDR) | Public entrypoint (can lock to your CIDR in DEV) |
| ECS Service (App) | 8080 | ALB SG | Only reachable through the ALB |
| RDS (Postgres) | 5432 | ECS Service SG (+ optional your IP) | App-only access; temp allow your IP for debugging |
| MSK Serverless | 9098 | ECS Service SG | SASL/IAM over TLS (SASL_SSL) |
Here’s a visual representation of the security groups and their relationships:

Here’s the Terraform configuration for the security groups:
resource "aws_security_group" "alb" {
name = "ot-alb-sg"
description = "ALB 80/443 in, all out"
vpc_id = local.vpc_id
# Always open port 80 for HTTP.
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
# Conditionally open port 443 for HTTPS when enable_https=true.
dynamic "ingress" {
for_each = var.enable_https ? [1] : []
content {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}
# Egress fully open (0.0.0.0/0 + ::/0). This is common for ALBs since
# the target group traffic must flow to ECS tasks or health checks.
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}resource "aws_security_group" "svc" {
name = "ot-svc-sg"
vpc_id = local.vpc_id
ingress {
from_port = var.container_port
to_port = var.container_port
protocol = "tcp"
security_groups = [aws_security_group.alb.id] # restrict inbound to ALB only
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}resource "aws_security_group" "rds" {
name = "ot-rds-sg"
vpc_id = data.aws_vpc.this.id
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Allow ECS service tasks to connect to RDS Postgres (port 5432).
# Target is the RDS SG created in bootstrap, with ingress scoped
# to the ECS service SG only.
resource "aws_security_group_rule" "rds_from_ecs_5432" {
type = "ingress"
security_group_id = data.terraform_remote_state.bootstrap.outputs.rds_sg_id
from_port = 5432
to_port = 5432
protocol = "tcp"
source_security_group_id = aws_security_group.svc.id
description = "Allow Postgres (5432) from ECS service"
}resource "aws_security_group" "msk" {
name = "ot-msk-sls-sg"
description = "Security Group for MSK Serverless"
vpc_id = local.vpc_id
# Allow all egress so clients can reach broker endpoints and AWS services as needed.
# Inbound is intentionally empty here; client-to-broker flows are initiated outbound.
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Allow ECS service tasks to connect to MSK over IAM-authenticated TLS (port 9098).
# The target SG is defined in bootstrap, and this rule grants ingress specifically
# from the ECS service SG in this environment.
resource "aws_security_group_rule" "msk_ingress_from_svc" {
type = "ingress"
security_group_id = data.terraform_remote_state.bootstrap.outputs.msk_sg_id
from_port = 9098
to_port = 9098
protocol = "tcp"
source_security_group_id = aws_security_group.svc.id
description = "Allow MSK IAM TLS (9098) from ECS service"
}Deploying the Application
Once the infrastructure is in place, the next step is to deploy the application itself. For this project, the application runs as a container on Amazon ECS (Fargate).
The deployment flow works like this:
- The application is packaged as a Docker image.
- The image is pushed to Amazon ECR.
- ECS pulls the latest image and runs it in a Fargate task inside the cluster.
Here’s a simplified example of the Terraform configuration for the ECS cluster and service:
# ECS cluster to host the service tasks.
resource "aws_ecs_cluster" "this" {
name = "order-tracking-cluster"
}
# Task definition for the application (Fargate).
# Uses awsvpc networking and injects config for MSK Serverless (IAM auth) and Postgres.
resource "aws_ecs_task_definition" "this" {
family = "order-tracking"
requires_compatibilities = ["FARGATE"]
network_mode = "awsvpc"
cpu = var.task_cpu
memory = var.task_memory
# Roles: execution for agent actions, task for app runtime permissions (from bootstrap).
execution_role_arn = data.aws_iam_role.task_execution.arn
task_role_arn = data.terraform_remote_state.bootstrap.outputs.ecs_task_role_arn
container_definitions = jsonencode([
{
name = "order-tracking"
image = "${data.aws_caller_identity.this.account_id}.dkr.ecr.${var.aws_region}.amazonaws.com/order-tracking:${var.image_tag}"
essential = true
portMappings = [{ containerPort = var.container_port, protocol = "tcp" }]
# App configuration via env vars. Keep secrets out of here; use the 'secrets' block instead.
environment = [
{ name = "SPRING_PROFILES_ACTIVE", value = var.spring_profile },
# Kafka (MSK Serverless) over IAM on port 9098.
{ name = "SPRING_KAFKA_BOOTSTRAP_SERVERS", value = data.terraform_remote_state.bootstrap.outputs.msk_bootstrap_brokers },
{ name = "SPRING_KAFKA_PROPERTIES_SECURITY_PROTOCOL", value = "SASL_SSL" },
{ name = "SPRING_KAFKA_PROPERTIES_SASL_MECHANISM", value = "AWS_MSK_IAM" },
{ name = "SPRING_KAFKA_PROPERTIES_SASL_JAAS_CONFIG", value = "software.amazon.msk.auth.iam.IAMLoginModule required;" },
{ name = "SPRING_KAFKA_PROPERTIES_SASL_CLIENT_CALLBACK_HANDLER_CLASS", value = "software.amazon.msk.auth.iam.IAMClientCallbackHandler" },
# JDBC URL built from bootstrap outputs. Credentials are injected as ECS secrets below.
{ name = "SPRING_DATASOURCE_URL", value = "jdbc:postgresql://${data.terraform_remote_state.bootstrap.outputs.rds_endpoint}:5432/${data.terraform_remote_state.bootstrap.outputs.rds_db_name}" }
]
# ECS-managed injection from Secrets Manager. The ":json-key::" suffix selects the field.
# Example: arn:...:secret:ot/rds/postgres-XXXX:username:: → fetches {"username": "...", "password": "..."}[username]
secrets = [
{ name = "SPRING_DATASOURCE_USERNAME", valueFrom = "${data.terraform_remote_state.bootstrap.outputs.rds_secret_arn}:username::" },
{ name = "SPRING_DATASOURCE_PASSWORD", valueFrom = "${data.terraform_remote_state.bootstrap.outputs.rds_secret_arn}:password::" }
]
# CloudWatch Logs configuration.
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-group = aws_cloudwatch_log_group.ecs.name
awslogs-region = var.aws_region
awslogs-stream-prefix = "ecs"
}
}
}
])
}
# Fargate service fronted by the ALB.
# Tasks are launched in the subnets exported from bootstrap; assigning a public IP keeps dev simple.
resource "aws_ecs_service" "this" {
name = "order-tracking-svc"
cluster = aws_ecs_cluster.this.id
task_definition = aws_ecs_task_definition.this.arn
desired_count = var.desired_count
launch_type = "FARGATE"
network_configuration {
subnets = data.terraform_remote_state.bootstrap.outputs.msk_client_subnet_ids
security_groups = [aws_security_group.svc.id]
assign_public_ip = true # For DEV without NAT; switch off when moving to private subnets.
}
load_balancer {
target_group_arn = aws_lb_target_group.this.arn
container_name = "order-tracking"
container_port = var.container_port
}
# Ensure the ALB listener exists before registering targets.
depends_on = [aws_lb_listener.http]
}This configuration ensures that ECS can run the container using the image stored in ECR, attach it to the VPC subnets, and automatically push logs into CloudWatch.
Here’s how the ECS cluster looks in the AWS Console:
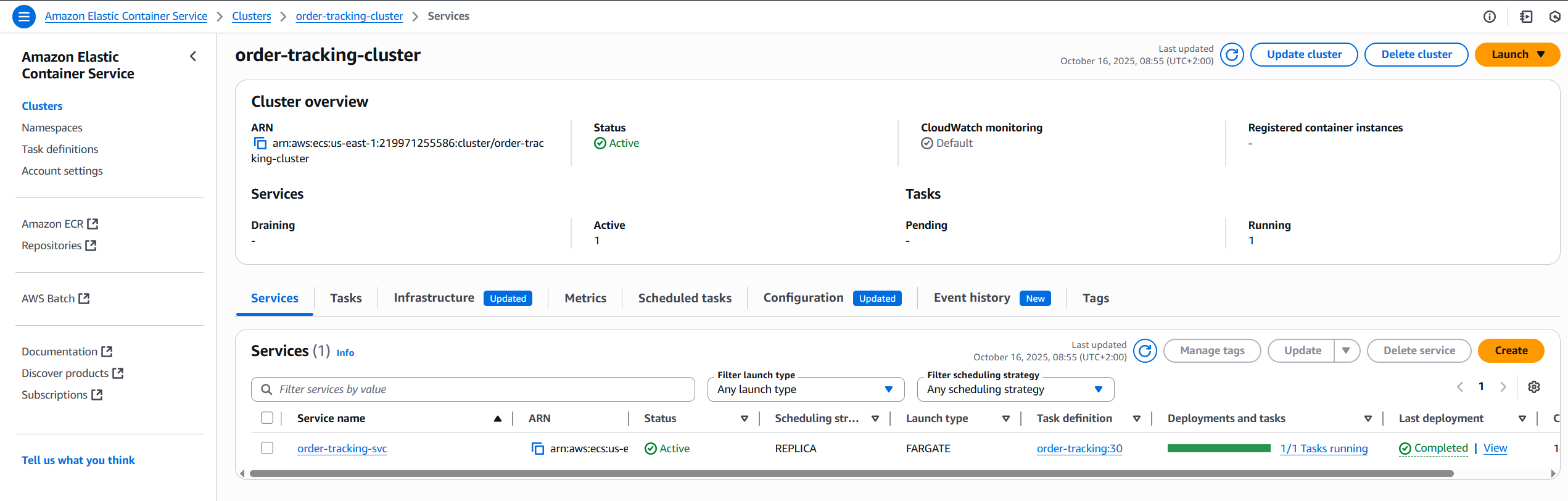
Observability with CloudWatch
As you can see above, the ECS task definition includes a logConfiguration that sends all container logs directly to Amazon CloudWatch. This allows every Spring Boot log line (System.out, errors, requests, etc.) to be automatically streamed into a CloudWatch Log Group without requiring any extra agents or SSH access to servers.
With this setup, I can open the AWS Console, go to CloudWatch, and search or filter logs per service and task in real time. This makes debugging much easier, especially in a pre-production environment where quick feedback is critical.
Centralizing both logs and metrics in CloudWatch provides better visibility into the health of the application and lays the foundation for future improvements like setting up alerts, dashboards, or integrating with external observability tools (e.g., Prometheus or Grafana).
Here’s a screenshot of the CloudWatch Log Group with application logs:
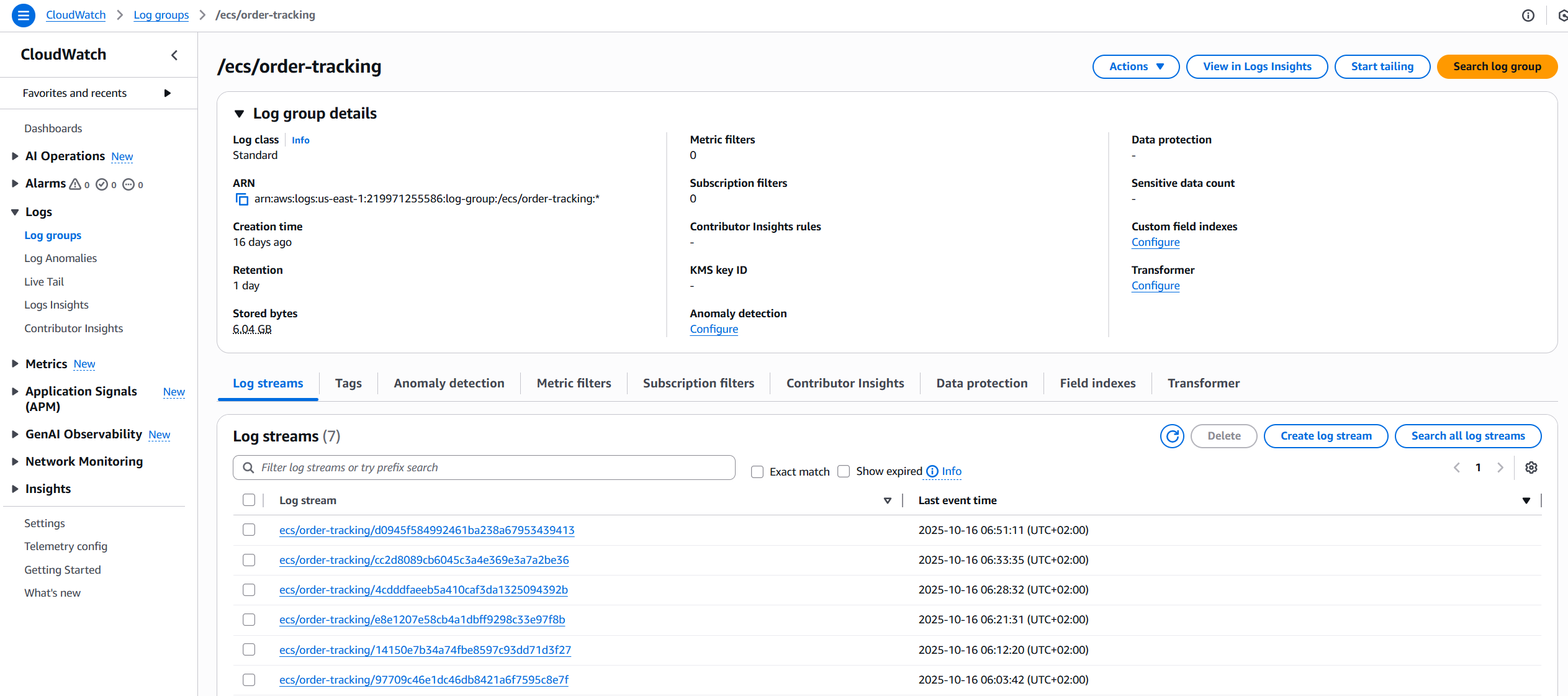
End-to-End Testing
Once the service was deployed, I validated the setup with real requests using Postman. This allowed me to confirm that the ECS service was reachable through the Application Load Balancer and that requests were being processed correctly.
Postman request hitting the service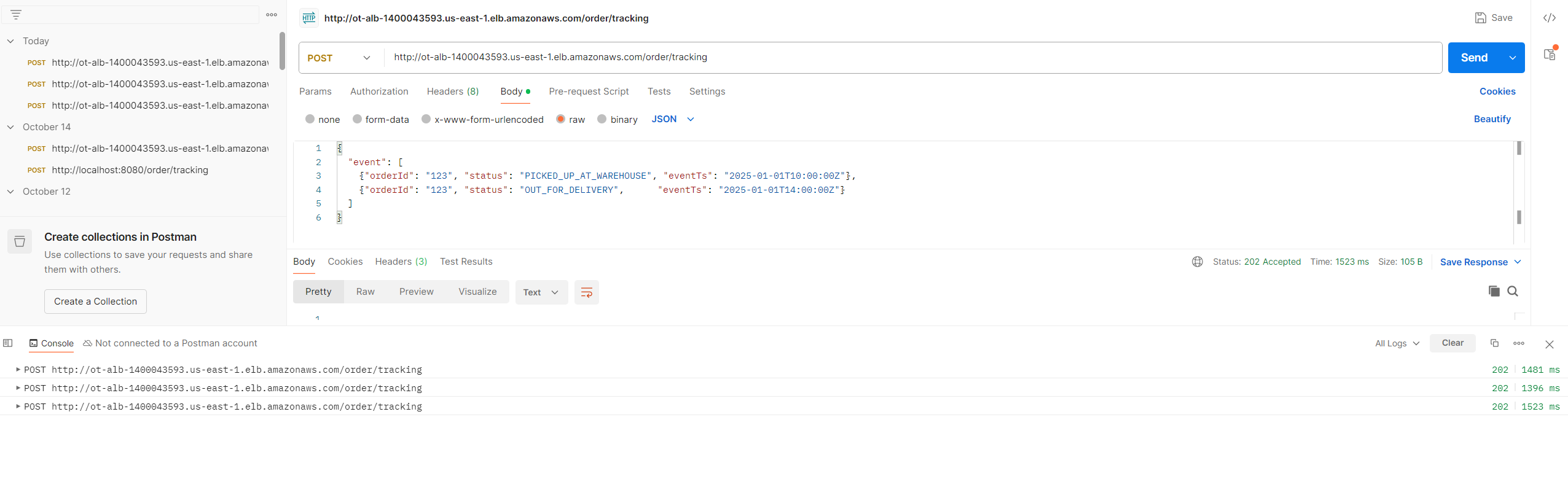
The corresponding logs appeared in CloudWatch, showing how the application handled the request:
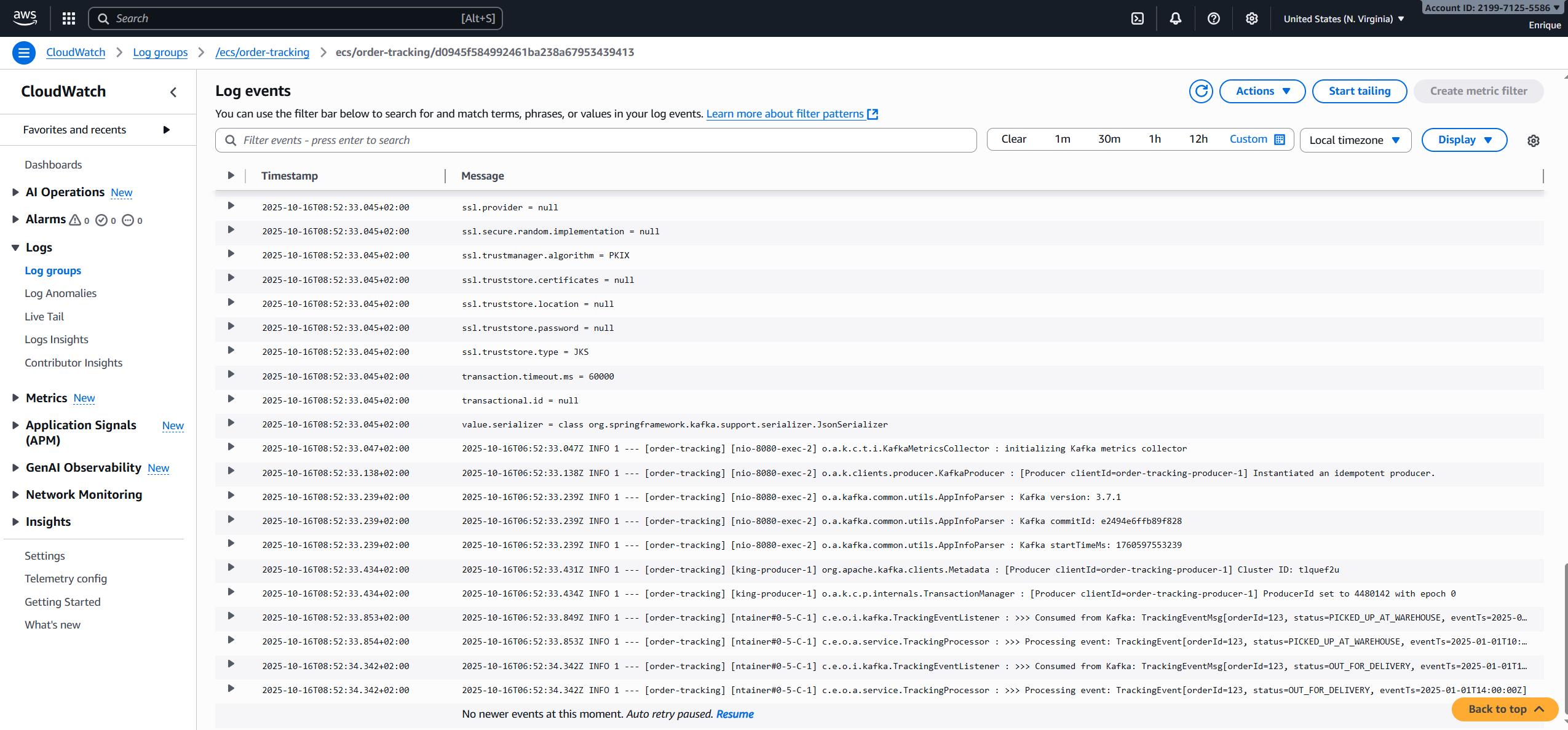
Finally, I verified that the data was persisted correctly in PostgreSQL (RDS). To make this possible from my local machine, I temporarily allowed inbound traffic from my public IP in the RDS security group. This is something you would avoid in production, but it’s useful in pre-production for quick debugging and validation.
Querying the RDS database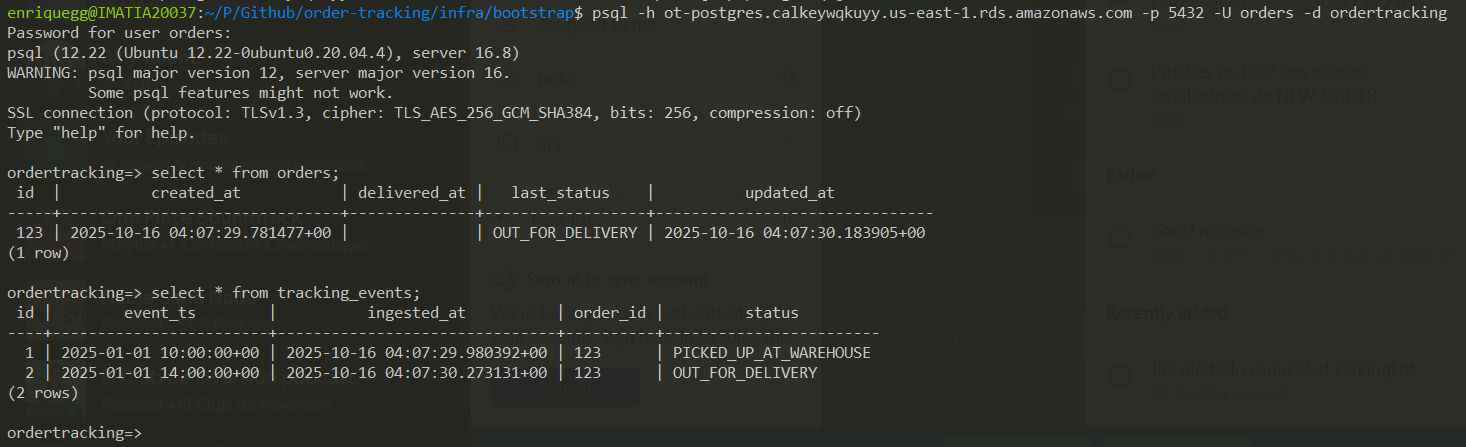
Application Configuration
To keep local development separate from the cloud setup, I created a new Spring profile named aws. This profile activates when the service is deployed on AWS and overrides the local configuration.
Here’s an excerpt from the application-aws.yml:
spring:
config:
activate:
on-profile: aws
datasource:
url: ${SPRING_DATASOURCE_URL} # e.g. jdbc:postgresql://<rds-endpoint>:5432/<db>?sslmode=require
username: ${SPRING_DATASOURCE_USERNAME}
password: ${SPRING_DATASOURCE_PASSWORD}
driver-class-name: org.postgresql.Driver
jpa:
database-platform: org.hibernate.dialect.PostgreSQLDialect
kafka:
bootstrap-servers: ${SPRING_KAFKA_BOOTSTRAP_SERVERS} # e.g. b-xxxx.kafka-serverless.us-east-1.amazonaws.com:9098
properties:
security.protocol: SASL_SSL
sasl.mechanism: AWS_MSK_IAM
sasl.jaas.config: software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class: software.amazon.msk.auth.iam.IAMClientCallbackHandler
admin:
fail-fast: true
properties:
security.protocol: SASL_SSL
sasl.mechanism: AWS_MSK_IAM
sasl.jaas.config: software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class: software.amazon.msk.auth.iam.IAMClientCallbackHandlerApplication-Level Changes
To integrate with AWS services, I had to introduce a few changes in the Spring Boot application itself:
Added the MSK IAM authentication library (software.amazon.msk:aws-msk-iam-auth) as a dependency:
<dependency>
<groupId>software.amazon.msk</groupId>
<artifactId>aws-msk-iam-auth</artifactId>
<version>2.0.3</version>
</dependency>Declared the Kafka topics explicitly at startup to ensure they are created and configured correctly in MSK:
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic trackingEventsTopic() {
return TopicBuilder.name(KafkaTopics.TRACKING_EVENTS).partitions(6).build();
}
}Automation with GitHub Actions
With the infrastructure defined in Terraform and the application containerized, the last step is to fully automate the deployment pipeline. For this, I used GitHub Actions, which builds the Docker image, pushes it to Amazon ECR, and then applies the Terraform configuration in the infra/env/ folder.
The flow looks like this:
- Trigger on every push to the
mainbranch (or when creating a release). - Build the Docker image of the Spring Boot application.
- Authenticate with AWS and push the image to ECR.
- Run
terraform initandterraform applyto provision/update the environment. - ECS automatically pulls the latest image and redeploys the service.
Here’s a simplified version of the GitHub Actions workflow (.github/workflows/deploy-aws-dev.yml):
name: Deploy DEV (ECS)
on:
push:
branches: ['feature/infra-aws', 'develop']
pull_request: { branches: [develop] }
workflow_dispatch:
permissions:
id-token: write # needed for OIDC
contents: read
env:
AWS_REGION: us-east-1
TF_WORKSPACE: dev
jobs:
deploy:
runs-on: ubuntu-latest
environment: dev
steps:
- uses: actions/checkout@v4
- name: Configure AWS creds (OIDC) # assume role via GitHub OIDC, no static keys
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ vars.AWS_DEV_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to ECR # so docker can push image
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build & Push image # build with commit SHA
env:
ECR_REPO: order-tracking
REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
docker build -f deploy/Dockerfile -t $REGISTRY/$ECR_REPO:$IMAGE_TAG .
docker push $REGISTRY/$ECR_REPO:$IMAGE_TAG
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
- name: Terraform Init + Workspace
working-directory: infra/env
run: |
terraform init
- name: Terraform Plan
working-directory: infra/env
run: |
terraform plan \
-var="image_tag=${{ github.sha }}" \
-var="spring_profile=aws" \
-var="enable_https=false"
- name: Terraform Apply
working-directory: infra/env
run: |
terraform apply -auto-approve \
-var="image_tag=${{ github.sha }}" \
-var="spring_profile=aws" \
-var="enable_https=false"
- name: Show URL
working-directory: infra/env
run: terraform output app_url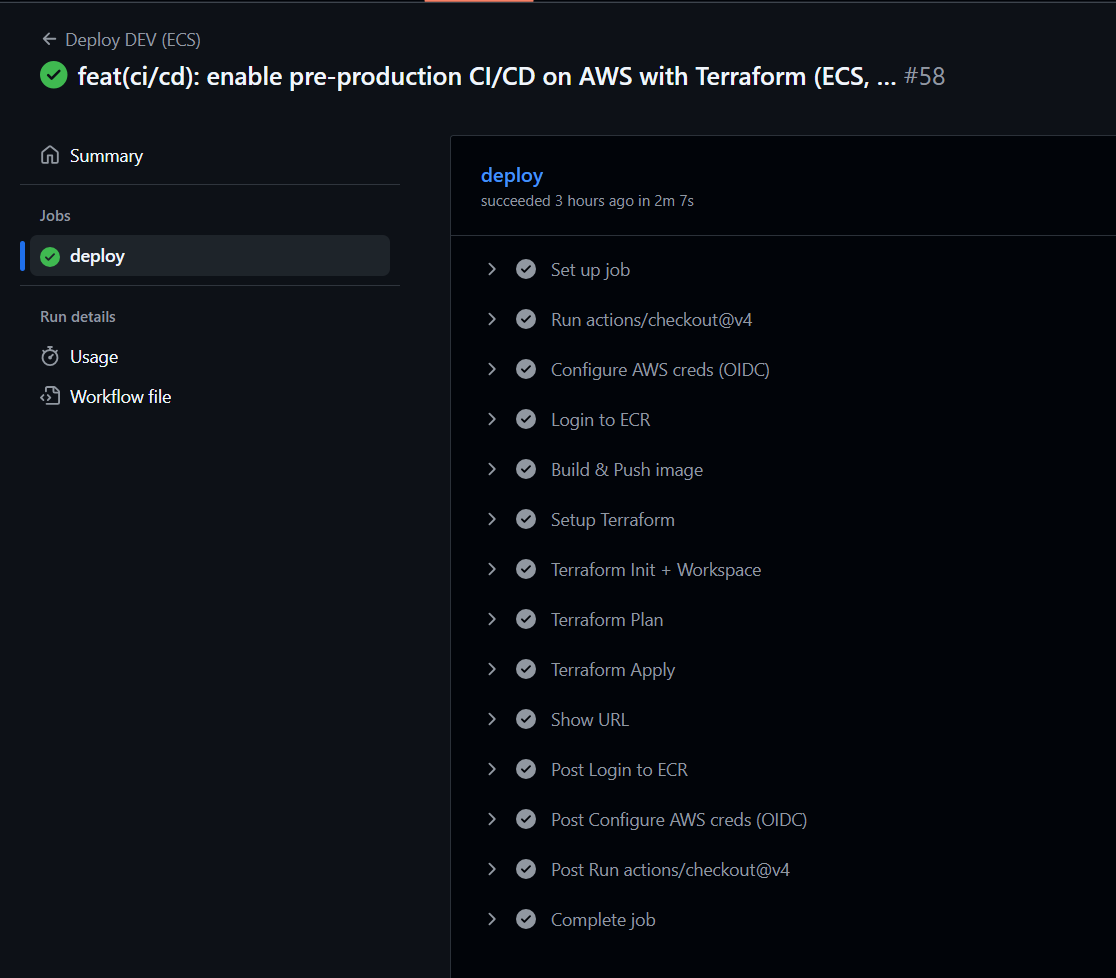
Conclusions and Key Highlights
This portfolio project demonstrates how a cloud-native service can be deployed on AWS with a production-ready approach, even in a pre-production environment. The setup brings together modern practices such as Infrastructure as Code, automated CI/CD pipelines, and observability out of the box.
Key highlights from this architecture:
- Terraform organization matters: splitting bootstrap and environment code helps avoid accidental re-creation of global resources.
- Profiles in Spring Boot are key: creating an
awsprofile made it easy to separate local development from cloud deployment. - Automation saves time: with GitHub Actions, deployments are reproducible and consistent with a simple
git push. - Observability is non-negotiable: having logs and metrics in CloudWatch makes debugging and monitoring much easier.
- Flexibility in pre-production: using public subnets with strict security groups allowed remote access and faster testing cycles.
What’s next?
While this setup is already functional, there are areas I’d like to improve in the future:
- Adding alerts and dashboards in CloudWatch.
- Exploring Prometheus/Grafana for richer observability.
- Defining more advanced scaling policies for ECS tasks.
- Expanding to a multi-environment setup (staging, production) with isolated pipelines.
Overall, this architecture provides a strong foundation for reliable deployments and showcases how to bring production-grade practices into a portfolio project.